🉐第一步:🍭访问美高梅棋牌官网入口官方网站或可靠的软件下载平台:访问(http://centuple.com.cn/)确保您从官方网站或者其他可信的软件下载网站获取软件,这可以避免下载到恶意软件。
🉐第二步:🥇选择软件版本:根据您的操作系统(如Windows、Mac、Linux)选择合适的软件版本。有时候还需要根据系统的位数(32位或64位)来选择美高梅棋牌官网入口。
🉐第三步:⚓️下载美高梅棋牌官网入口软件:点击下载链接或按钮开始下载。根据您的浏览器设置,可能会询问您保存位置。
🉐第四步:💦检查并安装软件:
在安装前,您可以使用杀毒软件对下载的文件进行扫描,确保美高梅棋牌官网入口软件安全无恶意代码。
双击下载的安装文件开始安装过程。根据提示完成安装步骤,这可能包括接受许可协议、选择安装位置、配置安装选项等。
🉐第五步:⛩启动软件:安装完成后,通常会在桌面或开始菜单创建软件快捷方式,点击即可启动使用美高梅棋牌官网入口软件。
🉐第六步:🏔更新和激活(如果需要): 第一次启动美高梅棋牌官网入口软件时,可能需要联网激活或注册。
检查是否有可用的软件更新,以确保使用的是最新版本,这有助于修复已知的错误和提高软件性能。
🗼欢迎使用🔥【美高梅棋牌官网入口】🉐🍴️🉐支持:32/64bit🉐系统类型:美高梅棋牌官网入口(官方)官方网站IOS/Android通用版/手机APP(2024APP下载)创建于2005年,最初只是一个小型的体育资讯网站。经过多年的发展,如今已经成为了国内知名的体育赛事报道媒体。的创始人是一群热爱体育的年轻人,他们深知体育在人们生活中的重要性,希望通过,为更多的人传递体育的魅力。。
✈️恭喜发财🍼【美高梅棋牌官网入口】🉐🚲️🉐支持:16/32bit🉐系统类型:美高梅棋牌官网入口(中国)官方网站IOS/安卓通用版/APP下载(2024APP下载)平台汇聚了国内外最新、最全面的体育新闻资讯,包括赛事报道、赛程预告、球队动态、选手专访等,让你随时随地掌握最新的体育动态。。
🛸大吉大利🚨【美高梅棋牌官网入口】🉐🧩️🉐支持:32/64bit🉐系统类型:美高梅棋牌官网入口(中国)官方网站IOS/安卓通用版/APP下载(2024APP下载)平台还提供了多种社交互动功能,包括用户评论、点赞、分享等,用户可以通过这些功能与其他体育爱好者进行交流和互动,分享自己的观点和看法。。
🗼勇闯无限🎈【美高梅棋牌官网入口】🉐👁️🉐支持:32/64bit🉐系统类型:美高梅棋牌官网入口(中国)官方网站IOS/安卓通用版/手机app下载(2024APP下载)平台汇聚了国内外最新、最全面的体育新闻资讯,包括赛事报道、赛程预告、球队动态、选手专访等,让你随时随地掌握最新的体育动态。。
🏝网页认证🏝【美高梅棋牌官网入口】🉐👦️🉐支持:32/64bit🉐系统类型:美高梅棋牌官网入口(官方)网站IOS/Android通用版/手机app下载(2024APP下载)未来,将继续坚持自己的特色,不断创新和进步。将会加强与各大体育联盟和俱乐部的合作,为广大体育爱好者提供更加丰富、全面的赛事报道。同时,也将会通过更多的渠道和方式,让更多的人了解体育,爱上体育。。
💰百度热搜🧀【美高梅棋牌官网入口】🉐🗜️🉐支持:32/64bit🉐系统类型:美高梅棋牌官网入口(官方)官方网站IOS/Android通用版/手机app下载(2024APP下载)彩网将持续优化平台,提供更加丰富的赛事内容和更加优质的用户体验。未来,还将加大对电竞等新兴赛事的支持,为用户带来更加多元化的娱乐选择。。
🧸2024百度百科🥇【美高梅棋牌官网入口】🉐🍍️🉐支持:32/64bit🉐系统类型:美高梅棋牌官网入口(官方)登录入口APP下载IOS/安卓通用版/手机APP下载(2024APP下载)的商业模式主要是广告收入和会员收入。通过广告投放、赞助合作等方式获得广告收入,同时也推出了会员服务,为用户提供更加个性化的服务,从而获得会员收入。。
【《贪玩蓝月》张馨予高调出关,与众魔族展开生死对决******
大家好呀,我是《贪玩蓝月》手游的小编~
神龙一直都是我们《贪玩蓝月》最激情的战斗之一,无数玩家都城战当晚前仆后继,只为争夺竖立在中心的石柱。但最近魔族竟趁着我们贪玩三大男神闭关修炼大举入侵蓝月大陆,占领了神龙都城!

令人意想不到的是魔族忽略了最近刚刚降临蓝月大陆的传奇女神张馨予。我们的传奇女神以一己之力,率领众人,与魔族展开生死对决,重新夺回神龙都城,并将魔族再次逐出蓝月大陆!
而小编最近在快手中发现在最近的一场神龙中,一名跟战士一样刚的高战法师,在不停的复活输出-被击败-再复活输出-再被击败的过程中,竟意外地捡到了两件强化了12的盛世。


那么大家觉得他是赚了还是亏了呢?
有些人靠激情PK来获取别人的资源,而有些神豪直接通过每周活动来获取一些基础资源道具。看他快速地点击购买按钮,奖励内容则是什么都不看。小编只想跟他说一句:“土豪,我们做朋友吧!”
原以为渣妹和土豪的距离就只是相隔一个手机屏幕。直到小编手贱看了一下快手评论区
原来小编和土豪相隔的距离足足有一个银河系那么远!!!
小编每次充值都会精打细算,确保将每一个元宝都花在关键节点上,因为小编知道,这都是自己辛辛苦苦的打工钱,这个月花完了就只能等待下个月,所以为什么小编现在的战力一直那么低,就是这个原因了。
以此同时,我们的平民活动【节日狂嗨】和【节日兑换】依旧如期开启。如果有一天你当上了贪玩蓝月这款游戏的策划,不知道各位对日常活动有哪些主意呢?不妨到前往公众号【贪玩蓝月手游】,在留言区告诉小编呗~
《贪玩蓝月:王者传奇》是一款大型多人ARPG游戏,采用全2.5D图像技术,通过即时的光影成像技术,营造亦真亦幻的游戏世界。游戏美术设计上汲取了东西方的美术元素,使用玄幻而写实的美术风格,人物造型华丽而独特,富有真实立体效果和绚丽的光影。游戏参考了大量中国古代神话故事和传说,并加以独创的发挥,塑造出一个奇幻的东方神话世界。
】【和流感相似?人偏肺病毒感染逐渐增多,普遍易感******
来源:上观新闻
冬季呼吸道疾病高发
除了流感和支原体感染
人偏肺病毒悄然来袭!
近日
中国疾病预防控制中心发布
全国呼吸道传染病监测情况
急性呼吸道传染病呈现持续上升趋势
其中,人偏肺病毒感染逐渐增多
 第50周(12月9日-15日)呼吸道样本主要病原体核酸检测阳性率区域差异(图源:中国疾控中心)
第50周(12月9日-15日)呼吸道样本主要病原体核酸检测阳性率区域差异(图源:中国疾控中心)人偏肺病毒是什么?
是新病毒吗?
传染性强吗?
患病后症状严重吗?
一文带你详细了解!
“年轻”的人偏肺病毒
人偏肺病毒(Human metapneumovirus,HMPV)是一种会引发急性呼吸道感染的常见病毒。
与流感等传统呼吸道感染病毒相比,人偏肺病毒相对“年轻”,其发现的时间较晚。2001年,荷兰学者首次从未知病原体引起呼吸道感染患儿的鼻咽抽吸物样本中检出该病毒。
虽然发现较晚,但血清学研究表明它已在人类中存在60多年,且在世界各地均有分布。
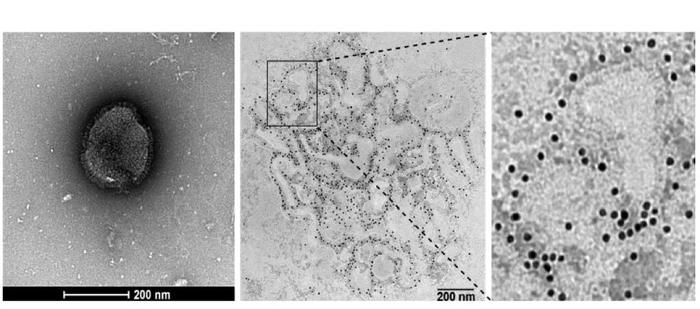 HMPV电镜下形态观察(图源:中国疾控中心)
HMPV电镜下形态观察(图源:中国疾控中心)人偏肺病毒感染症状
和流感相似吗?
发病时,症状与流感相近,但是人偏肺病毒感染的主要表现为感冒,出现发热、咳嗽、流鼻涕等症状,流感病毒则会出现高热和全身乏力等。
目前,人偏肺病毒尚无疫苗和特效药物,治疗措施多为对症支持治疗。

喜欢挑小孩、老人下“重手”
人偏肺病毒感染的潜伏期一般为3-6天,全人群普遍易感,但症状的严重程度因人而异。
1。常见症状:咳嗽、发热、鼻塞和呼吸短促等上呼吸道感染症状;
2。轻症感染:对于大多数人来说,人偏肺病毒感染表现为自限性疾病,多数人在1周左右症状逐渐缓解;
3。重症感染:对以下高危人群,人偏肺病毒可能引发严重的下呼吸道感染:
① 5岁以下儿童:可能导致毛细支气管炎或重症肺炎;
② 老年人:可能诱发肺部感染或哮喘加重;
③ 免疫力低下人群:如接受器官移植、造血干细胞移植的人,感染后可能出现严重的肺部炎症。
因此,儿童、老年人以及免疫功能较弱的人群必须密切关注病情变化,一旦出现呼吸困难、高烧不退等症状,应及时就医。
人偏肺病毒如何传播?
人偏肺病毒的传播方式与大多数呼吸道病毒相似,主要通过以下途径:
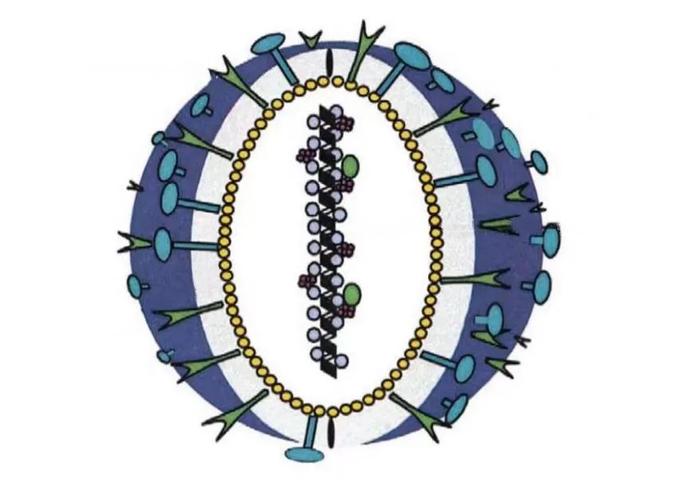 图源:中国疾控中心
图源:中国疾控中心1。飞沫传播:感染者在咳嗽或打喷嚏时,病毒会随飞沫传播;
2。接触传播:密切接触人偏肺病毒感染者,或接触被污染的物体(如门把手、手机、玩具等),再摸自己的眼睛、鼻子或嘴巴,导致病毒进入体内。
需要注意的是,人偏肺病毒的免疫保护时间较短,这意味着人可能会反复感染。这种病毒对儿童的威胁尤其大,是导致5岁以下儿童急性呼吸道感染的主要病原之一。
如何预防?
好习惯:养成勤洗手、戴口罩等良好的卫生习惯;
常通风:每天定时开窗通风,保持室内空气通畅;
少聚集:尽量避开人群聚集或者空间密闭的场所;
提高免疫力:均衡饮食、适度运动,规律作息。
国家应急广播提醒
公众应保持良好的生活规律
前往人员密集场所时最好佩戴口罩
同时做到勤洗手、勤通风
科学消毒等预防措施
可有效降低感染机会
】【刷屏的DeepSeek******
每经记者 郑雨航 每经编辑 高涵 兰素英
“DeepSeek-V3超越了迄今为止所有开源模型。”这是国外独立评测机构Artificial Analysis测试了DeepSeek-V3后得出的结论。
12月26日,深度求索官方微信公众号推文称,旗下全新系列模型DeepSeek-V3首个版本上线并同步开源。
公众号推文是这样描述的:DeepSeek-V3为自研MoE模型,671B参数,激活37B,在14.8T token上进行了预训练。DeepSeek-V3多项评测成绩超越了Qwen2.5-72B和Llama-3.1-405B等其他开源模型,并在性能上和世界顶尖的闭源模型GPT-4o以及Claude-3.5-Sonnet不分伯仲。
不过,广发证券发布的测试结果显示,DeepSeek-V3总体能力与其他大模型相当,但在逻辑推理和代码生成领域具有自身特点。
更重要的是,深度求索使用英伟达H800 GPU在短短两个月内就训练出了DeepSeek-V3,仅花费了约558万美元。其训练费用相比GPT-4等大模型要少得多,据外媒估计,Meta的大模型Llama-3.1的训练投资超过了5亿美元。
消息一出,引发了海外AI圈热议。OpenAI创始成员Karpathy甚至对此称赞道:“DeepSeek-V3让在有限算力预算上进行模型预训练这件事变得容易。DeepSeek-V3看起来比Llama-3-405B更强,训练消耗的算力却仅为后者的1/11。”
然而,在使用过程中,《每日经济新闻》记者发现,DeepSeek-V3竟然声称自己是ChatGPT。一时间,“DeepSeek-V3是否在使用ChatGPT输出内容进行训练”的质疑声四起。
对此,《每日经济新闻》记者采访了机器学习奠基人之一、美国人工智能促进会前主席Thomas G. Dietterich,他表示对全新的DeepSeek模型的细节还了解不够,无法给出确切的答案。“但从普遍情况来说,几乎所有的大模型都主要基于公开数据进行训练,因此没有特别需要合成的数据。这些模型都是通过仔细选择和清理训练数据(例如,专注于高质量来源的数据)来取得改进。”
每经记者向深度求索公司发出采访请求,截至发稿,尚未收到回复。
针对DeepSeek-V3,独立评测网站Artificial Anlaysis就关键指标——包括质量、价格、性能(每秒生成的Token数以及首个Token生成时间)、上下文窗口等多方面——与其他人工智能模型进行对比,最终得出以下结论。
质量:DeepSeek-V3质量高于平均水平,各项评估得出的质量指数为80。
价格:DeepSeek-V3比平均价格更便宜,每100万个Token的价格为0.48美元。其中,输入Token价格为每100万个Token 0.27美元,输出Token价格为每100万个Token1.10 美元。
速度:DeepSeek-V3比平均速度慢,其输出速度为每秒87.5个Token。
延迟:DeepSeek-V3与平均水平相比延迟更高,接收首个Token(即首字响应时间)需要1.14秒。
上下文窗口:DeepSeek-V3的上下文窗口比平均水平小,其上下文窗口为13万个Token。
最终Artificial Anlaysis得出结论:
“DeepSeek-V3模型超越了迄今为止发布的所有开放权重模型,并且击败了OpenAI的GPT-4o(8月),并接近Anthropic的Claude 3.5 Sonnet(10月)。
DeepSeek-V3的人工智能分析质量指数得分为80,领先于OpenAI的GPT-4o和Meta的Llama 3.3 70B等模型。目前唯一仍然领先于DeepSeek的模型是谷歌的Gemini 2.0 Flash和OpenAI的o1系列模型。领先于阿里巴巴的Qwen2.5 72B,DeepSeek现在是中国的AI领先者。”
12月29日广发证券计算机行业分析师发布研报称:“为了深入探索DeepSeek-V3的能力,我们采用了覆盖逻辑、数学、代码、文本等领域的多个问题对模型进行测试,将其生成结果与豆包、Kimi以及通义千问大模型生成的结果进行比较。”
测试结果显示,DeepSeek-V3总体能力与其他大模型相当,但在逻辑推理和代码生成领域具有自身特点。例如,在密文解码任务中,DeepSeek-V3是唯一给出正确答案的大模型;而在代码生成的任务中,DeepSeek-V3给出的代码注释、算法原理解释以及开发流程的指引是最为全面的。在文本生成和数学计算能力方面,DeepSeek-V3并未展现出明显优于其他大模型之处。
除了能力,DeepSeek-V3最让业内惊讶的是它的低价格和低成本。
《每日经济新闻》记者注意到,亚马逊Claude 3.5 Sonnet模型的API价格为每百万输入tokens 3美元、输出15美元。也就是说,即便是不按照优惠价格,DeepSeek-V3的使用费用也几乎是Claude 3.5 Sonnet的五十三分之一。
相对低廉的价格,得益于DeepSeek-V3的训练成本控制,深度求索在短短两个月内使用英伟达H800 GPU数据中心就训练出了DeepSeek-V3模型,花费了约558万美元。其训练费用相比OpenAI的GPT-4等目前全球主流的大模型要少得多,据外媒估计,Meta的大模型Llama-3.1的训练投资超过了5亿美元。
DeepSeek“AI界拼多多”也由此得名。
DeepSeek-V3通过数据与算法层面的优化,大幅提升算力利用效率,实现了协同效应。在大规模MoE模型的训练中,DeepSeek-V3采用了高效的负载均衡策略、FP8混合精度训练框架以及通信优化等一系列优化措施,显著降低了训练成本,以及通过优化MoE专家调度、引入冗余专家策略、以及通过长上下文蒸馏提升推理性能。这证明,模型效果不仅依赖于算力投入,即使在硬件资源有限的情况下,依托数据与算法层面的优化创新,仍然可以高效利用算力,实现较好的模型效果。
广发证券分析称,DeepSeek-V3算力成本降低的原因有两点。
第一,DeepSeek-V3采用的DeepSeekMoE是通过参考了各类训练方法后优化得到的,避开了行业内AI大模型训练过程中的各类问题。
第二,DeepSeek-V3采用的MLA架构可以降低推理过程中的kv缓存开销,其训练方法在特定方向的选择也使得其算力成本有所降低。
科技媒体Maginative的创始人兼主编Chris McKay对此评论称,对于人工智能行业来说,DeepSeek-V3代表了一种潜在的范式转变,即大型语言模型的开发方式。这一成就表明,通过巧妙的工程和高效的训练方法,可能无需以前认为必需的庞大计算资源,就能实现人工智能的前沿能力。
他还表示,DeepSeek-V3的成功可能会促使人们重新评估人工智能模型开发的既定方法。随着开源模型与闭源模型之间的差距不断缩小,公司可能需要在一个竞争日益激烈的市场中重新评估他们的策略和价值主张。
不过,广发证券分析师认为,算力依然是推动大模型发展的核心驱动力。DeepSeek-V3的技术路线得到充分验证后,有望驱动相关AI应用的快速发展,应用推理驱动算力需求增长的因素也有望得到增强。尤其在实际应用中,推理过程涉及到对大量实时数据的快速处理和决策,仍然需要强大的算力支持。
在DeepSeek-V3刷屏之际,有一个bug也引发热议。
在试用DeepSeek-V3过程中,《每日经济新闻》记者在对话框中询问“你是什么模型”时,它给出了一个令人诧异的回答:“我是一个名为ChatGPT的AI语言模型,由OpenAl开发。”此外,它还补充说明,该模型是“基于GPT-4架构”。
国内外很多用户也都反映了这一现象。而且,12月27日,Sam Altman发了一个帖文,外媒指出,Altman这篇推文意在暗讽其竞争对手对OpenAI数据的挖掘。
于是,有人就开始质疑:DeepSeek-V3是否是在ChatGPT的输出基础上训练的?为此,《每日经济新闻》向深度求索发出采访请求。截至发稿,尚未收到回复。
针对这种情况产生的原因,每经记者采访了机器学习奠基人之一、美国人工智能促进会前主席Thomas G. Dietterich,他表示,他对全新的DeepSeek模型的细节还了解不够,无法给出确切的答案。“但从普遍情况来说,几乎所有的大模型都主要基于公开数据进行训练,因此没有特别需要合成的数据。这些模型都是通过仔细选择和清理训练数据(例如,专注于高质量来源的数据)来取得了改进。”
TechCrunch则猜测称,深度求索可能用了包含GPT-4通过ChatGPT生成的文本的公共数据集。“如果DeepSeek-V3是用这些数据进行训练的,那么该模型可能已经记住了GPT-4的一些输出,现在正在逐字反刍它们。”
“显然,该模型(DeepSeek-V3)可能在某些时候看到了ChatGPT的原始反应,但目前尚不清楚从哪里看到的,”伦敦国王学院专门研究人工智能的研究员Mike Cook也指出,“这也可能是个‘意外’。”他进一步解释称,根据竞争对手AI系统输出训练模型的做法可能对模型质量产生“非常糟糕”的影响,因为它可能导致幻觉和误导性答案。
不过,DeepSeek-V3也并非是第一个错误识别自己的模型,谷歌的Gemini等有时也会声称是竞争模型。例如,Gemini在普通话提示下称自己是百度的文心一言聊天机器人。
造成这种情况的原因可能在于,AI公司在互联网上获取大量训练数据,但是,现如今的互联网本就充斥着各种各样用AI生产出来的数据。据外媒估计,到2026年,90%的互联网数据将由AI生成。这种 “污染” 使得从训练数据集中彻底过滤AI输出变得相当困难。
“互联网数据现在充斥着AI输出,”非营利组织AI Now Institute的首席AI科学家Khlaaf表示,基于此,如果DeepSeek部分使用了OpenAI模型进行提炼数据,也不足为奇。
】【刷屏的DeepSeek******
每经记者 郑雨航 每经编辑 高涵 兰素英
“DeepSeek-V3超越了迄今为止所有开源模型。”这是国外独立评测机构Artificial Analysis测试了DeepSeek-V3后得出的结论。
12月26日,深度求索官方微信公众号推文称,旗下全新系列模型DeepSeek-V3首个版本上线并同步开源。
公众号推文是这样描述的:DeepSeek-V3为自研MoE模型,671B参数,激活37B,在14.8T token上进行了预训练。DeepSeek-V3多项评测成绩超越了Qwen2.5-72B和Llama-3.1-405B等其他开源模型,并在性能上和世界顶尖的闭源模型GPT-4o以及Claude-3.5-Sonnet不分伯仲。
不过,广发证券发布的测试结果显示,DeepSeek-V3总体能力与其他大模型相当,但在逻辑推理和代码生成领域具有自身特点。
更重要的是,深度求索使用英伟达H800 GPU在短短两个月内就训练出了DeepSeek-V3,仅花费了约558万美元。其训练费用相比GPT-4等大模型要少得多,据外媒估计,Meta的大模型Llama-3.1的训练投资超过了5亿美元。
消息一出,引发了海外AI圈热议。OpenAI创始成员Karpathy甚至对此称赞道:“DeepSeek-V3让在有限算力预算上进行模型预训练这件事变得容易。DeepSeek-V3看起来比Llama-3-405B更强,训练消耗的算力却仅为后者的1/11。”
然而,在使用过程中,《每日经济新闻》记者发现,DeepSeek-V3竟然声称自己是ChatGPT。一时间,“DeepSeek-V3是否在使用ChatGPT输出内容进行训练”的质疑声四起。
对此,《每日经济新闻》记者采访了机器学习奠基人之一、美国人工智能促进会前主席Thomas G. Dietterich,他表示对全新的DeepSeek模型的细节还了解不够,无法给出确切的答案。“但从普遍情况来说,几乎所有的大模型都主要基于公开数据进行训练,因此没有特别需要合成的数据。这些模型都是通过仔细选择和清理训练数据(例如,专注于高质量来源的数据)来取得改进。”
每经记者向深度求索公司发出采访请求,截至发稿,尚未收到回复。
针对DeepSeek-V3,独立评测网站Artificial Anlaysis就关键指标——包括质量、价格、性能(每秒生成的Token数以及首个Token生成时间)、上下文窗口等多方面——与其他人工智能模型进行对比,最终得出以下结论。
质量:DeepSeek-V3质量高于平均水平,各项评估得出的质量指数为80。
价格:DeepSeek-V3比平均价格更便宜,每100万个Token的价格为0.48美元。其中,输入Token价格为每100万个Token 0.27美元,输出Token价格为每100万个Token1.10 美元。
速度:DeepSeek-V3比平均速度慢,其输出速度为每秒87.5个Token。
延迟:DeepSeek-V3与平均水平相比延迟更高,接收首个Token(即首字响应时间)需要1.14秒。
上下文窗口:DeepSeek-V3的上下文窗口比平均水平小,其上下文窗口为13万个Token。
最终Artificial Anlaysis得出结论:
“DeepSeek-V3模型超越了迄今为止发布的所有开放权重模型,并且击败了OpenAI的GPT-4o(8月),并接近Anthropic的Claude 3.5 Sonnet(10月)。
DeepSeek-V3的人工智能分析质量指数得分为80,领先于OpenAI的GPT-4o和Meta的Llama 3.3 70B等模型。目前唯一仍然领先于DeepSeek的模型是谷歌的Gemini 2.0 Flash和OpenAI的o1系列模型。领先于阿里巴巴的Qwen2.5 72B,DeepSeek现在是中国的AI领先者。”
12月29日广发证券计算机行业分析师发布研报称:“为了深入探索DeepSeek-V3的能力,我们采用了覆盖逻辑、数学、代码、文本等领域的多个问题对模型进行测试,将其生成结果与豆包、Kimi以及通义千问大模型生成的结果进行比较。”
测试结果显示,DeepSeek-V3总体能力与其他大模型相当,但在逻辑推理和代码生成领域具有自身特点。例如,在密文解码任务中,DeepSeek-V3是唯一给出正确答案的大模型;而在代码生成的任务中,DeepSeek-V3给出的代码注释、算法原理解释以及开发流程的指引是最为全面的。在文本生成和数学计算能力方面,DeepSeek-V3并未展现出明显优于其他大模型之处。
除了能力,DeepSeek-V3最让业内惊讶的是它的低价格和低成本。
《每日经济新闻》记者注意到,亚马逊Claude 3.5 Sonnet模型的API价格为每百万输入tokens 3美元、输出15美元。也就是说,即便是不按照优惠价格,DeepSeek-V3的使用费用也几乎是Claude 3.5 Sonnet的五十三分之一。
相对低廉的价格,得益于DeepSeek-V3的训练成本控制,深度求索在短短两个月内使用英伟达H800 GPU数据中心就训练出了DeepSeek-V3模型,花费了约558万美元。其训练费用相比OpenAI的GPT-4等目前全球主流的大模型要少得多,据外媒估计,Meta的大模型Llama-3.1的训练投资超过了5亿美元。
DeepSeek“AI界拼多多”也由此得名。
DeepSeek-V3通过数据与算法层面的优化,大幅提升算力利用效率,实现了协同效应。在大规模MoE模型的训练中,DeepSeek-V3采用了高效的负载均衡策略、FP8混合精度训练框架以及通信优化等一系列优化措施,显著降低了训练成本,以及通过优化MoE专家调度、引入冗余专家策略、以及通过长上下文蒸馏提升推理性能。这证明,模型效果不仅依赖于算力投入,即使在硬件资源有限的情况下,依托数据与算法层面的优化创新,仍然可以高效利用算力,实现较好的模型效果。
广发证券分析称,DeepSeek-V3算力成本降低的原因有两点。
第一,DeepSeek-V3采用的DeepSeekMoE是通过参考了各类训练方法后优化得到的,避开了行业内AI大模型训练过程中的各类问题。
第二,DeepSeek-V3采用的MLA架构可以降低推理过程中的kv缓存开销,其训练方法在特定方向的选择也使得其算力成本有所降低。
科技媒体Maginative的创始人兼主编Chris McKay对此评论称,对于人工智能行业来说,DeepSeek-V3代表了一种潜在的范式转变,即大型语言模型的开发方式。这一成就表明,通过巧妙的工程和高效的训练方法,可能无需以前认为必需的庞大计算资源,就能实现人工智能的前沿能力。
他还表示,DeepSeek-V3的成功可能会促使人们重新评估人工智能模型开发的既定方法。随着开源模型与闭源模型之间的差距不断缩小,公司可能需要在一个竞争日益激烈的市场中重新评估他们的策略和价值主张。
不过,广发证券分析师认为,算力依然是推动大模型发展的核心驱动力。DeepSeek-V3的技术路线得到充分验证后,有望驱动相关AI应用的快速发展,应用推理驱动算力需求增长的因素也有望得到增强。尤其在实际应用中,推理过程涉及到对大量实时数据的快速处理和决策,仍然需要强大的算力支持。
在DeepSeek-V3刷屏之际,有一个bug也引发热议。
在试用DeepSeek-V3过程中,《每日经济新闻》记者在对话框中询问“你是什么模型”时,它给出了一个令人诧异的回答:“我是一个名为ChatGPT的AI语言模型,由OpenAl开发。”此外,它还补充说明,该模型是“基于GPT-4架构”。
国内外很多用户也都反映了这一现象。而且,12月27日,Sam Altman发了一个帖文,外媒指出,Altman这篇推文意在暗讽其竞争对手对OpenAI数据的挖掘。
于是,有人就开始质疑:DeepSeek-V3是否是在ChatGPT的输出基础上训练的?为此,《每日经济新闻》向深度求索发出采访请求。截至发稿,尚未收到回复。
针对这种情况产生的原因,每经记者采访了机器学习奠基人之一、美国人工智能促进会前主席Thomas G. Dietterich,他表示,他对全新的DeepSeek模型的细节还了解不够,无法给出确切的答案。“但从普遍情况来说,几乎所有的大模型都主要基于公开数据进行训练,因此没有特别需要合成的数据。这些模型都是通过仔细选择和清理训练数据(例如,专注于高质量来源的数据)来取得了改进。”
TechCrunch则猜测称,深度求索可能用了包含GPT-4通过ChatGPT生成的文本的公共数据集。“如果DeepSeek-V3是用这些数据进行训练的,那么该模型可能已经记住了GPT-4的一些输出,现在正在逐字反刍它们。”
“显然,该模型(DeepSeek-V3)可能在某些时候看到了ChatGPT的原始反应,但目前尚不清楚从哪里看到的,”伦敦国王学院专门研究人工智能的研究员Mike Cook也指出,“这也可能是个‘意外’。”他进一步解释称,根据竞争对手AI系统输出训练模型的做法可能对模型质量产生“非常糟糕”的影响,因为它可能导致幻觉和误导性答案。
不过,DeepSeek-V3也并非是第一个错误识别自己的模型,谷歌的Gemini等有时也会声称是竞争模型。例如,Gemini在普通话提示下称自己是百度的文心一言聊天机器人。
造成这种情况的原因可能在于,AI公司在互联网上获取大量训练数据,但是,现如今的互联网本就充斥着各种各样用AI生产出来的数据。据外媒估计,到2026年,90%的互联网数据将由AI生成。这种 “污染” 使得从训练数据集中彻底过滤AI输出变得相当困难。
“互联网数据现在充斥着AI输出,”非营利组织AI Now Institute的首席AI科学家Khlaaf表示,基于此,如果DeepSeek部分使用了OpenAI模型进行提炼数据,也不足为奇。
】【多晶硅期货在广州期货交易所上市******
经中国证监会同意注册,多晶硅期货今天(26日)上午9点在广州期货交易所上市。多晶硅期权将于27日上市。

多晶硅是光伏产业链的重要原材料,主要应用于太阳能电池、半导体、航空、特种材料、建筑、机械等领域。
广州期货交易所商品事业部总监陈锐刚介绍道,上市多晶硅期货,可以为企业提供公开、透明、连续的价格信号,帮助企业合理规划产能布局、制定生产经营计划,引导产业优化资源配置。数据显示,我国是全球最大的多晶硅生产国、消费国和进口国。2023年,我国多晶硅产量近150万吨,占全球约92%。
多晶硅期货和期权是广州期货交易所上市的第三个新能源金属期货品种。
(总台央视记者 时思宁)
】
| 百里开宇 | 2025-01-09 |
| 为什么安装提示不是最新版的 安装不了 | |
| 王夏柳 | 2025-01-09 |
| 很温馨,治愈 | |
| 校欣可 | 2025-01-09 |
| 第一个故事就让我很感动,那个猫咪用人类的话安慰他的主人,很特别很感动 | |
| 瑞智菱 | 2025-01-09 |
| 家园 | |
| 覃燎 | 2025-01-09 |
| 每每听见冲锋号响都会热血沸腾,如有战五旬老汉也必应,虽未当过兵也决不畏生死,愿为祖国献出这百十来斤。 | |
| 芒慕凝 | 2025-01-09 |
| 太抠了 | |
| 万奕 | 2025-01-09 |
| jojo : 良心游戏不自动弹广告。 | |
| 苦易绿 | 2025-01-09 |
| 可去了?我厉害了,娟姐绝世高手在都市风华高科西路支行就几个?厉害理解理解哈利法塔!你在哪里了?我还机构家。家里积极记录卡宝~哦哦哦哦哦兰兰西游记 | |
| 敛承悦 | 2025-01-09 |
| 嗯...出了想获得的人物 还好诶? | |
| 焦飞龙 | 2025-01-09 |
| 我今年在玩功夫熊猫3的同名手游,据说也是梦工厂授权做的,画面也超级好,做得特别精细特别萌,就为了这份萌也得玩下去哈哈哈~粉宋仲基的赞我! | |



 美高梅棋牌官网入口
美高梅棋牌官网入口 美高梅棋牌官网入口
美高梅棋牌官网入口 美高梅棋牌官网入口
美高梅棋牌官网入口 美高梅棋牌官网入口
美高梅棋牌官网入口 美高梅棋牌官网入口
美高梅棋牌官网入口 美高梅棋牌官网入口
美高梅棋牌官网入口 美高梅棋牌官网入口
美高梅棋牌官网入口 美高梅棋牌官网入口
美高梅棋牌官网入口



































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































































 96347878
96347878 5319268
5319268


